This is the third post of a three-part series about the new ways in which breach data can be beneficial for both offense and defense. Part one can be found HERE and part two is HERE.
Breach data is nothing new to investigators. I have explained how we ingest typical text-based breach data since the 7th edition of Open Source Intelligence Techniques. The new world of daily ransomware dumps and stealer logs changes everything. We are collecting this data in masses never seen before. As stated previously, we bring in over 2 Terabytes of new stolen content weekly, which we parse down to an average of 25 GB of useful data for the week. Our current collection is over 25TB, most of which is ransomware data. We focus mostly on text and private documents, and try to eliminate all public docs, company materials, and anything else which does not have an immediate impact on an individual. We bring everything into a locally-stored database available to the entire team.
Below is a heavily redacted screen capture of our internal investigations portal. In this example, I searched only the email address of my target. Since this address appears within multiple breaches, it connects me to her real name (from the MGM and LinkedIn breaches). From there, the system cross-references that name to her driver's license. This license was scanned by a mortgage company, which was later hit with a ransomware attack, which resulted in all of their data being published on an onion site. Our system scanned the characters within the scanned image but also the barcode, as explained in the previous posts. Now that our system has enough true data about our target, it can cross-reference everything within our collection of breach data, including ransomware dumps, Tor content, and stealer logs. From there it determines her home address, which is cross-referenced with people search data, historic Whois data, vehicle data, and numerous public APIs. The result is an immediate view of all available public, private, and stolen data. Our team relies heavily on this portal, and each query takes approximately 5-10 seconds. It cross-references any data we have until all options have been exhausted.
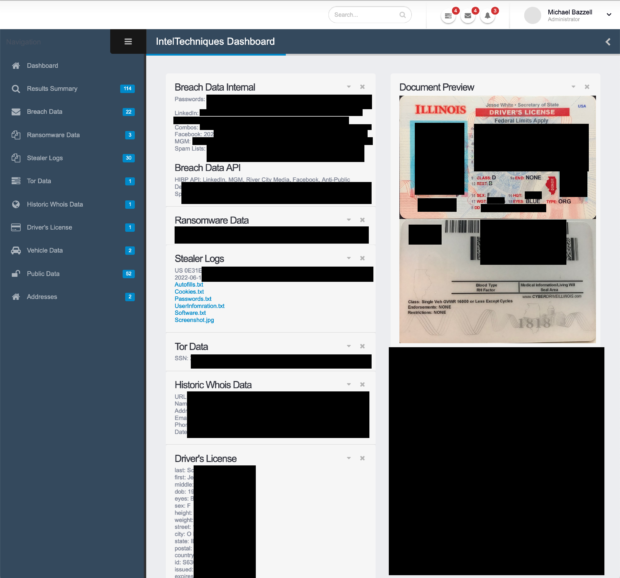
Maintaining our internal database is a full-time job for a member of our staff. I am confident he is overworked. The daily benefits of access to this data cannot be overstated, however, we currently do not offer this portal to third parties. Consider the following typical internal usage.
Internal Investigations: This one is obvious. This type of data can be crucial to investigations. It can immediately uncover real and alias information. Every day, breach data reveals the true person behind a burner account due to sloppy OPSEC.
Client Vetting: We take our clients' privacy very seriously. We would never use a third-party system to properly verify the identity of a potential client. Instead, we use our own in-house system to make sure we know who we are dealing with. At least twice, a potential client's record in our system revealed active warrants for arrest, identifying the reason they were asking about anonymous relocation services (we never assist in those situations).
Client Exposure: We have many clients who keep us on a retainer. Part of that service is an initial analysis of exposed information, and a constant monitoring for any new details. Every week, we reach out to clients to let them know of a new breach, ransomware attack, or password log which may impact them or their company. Just a few months ago, I was able to alert a close friend that his daughter's full name, address, DOB, SSN, and banking details were being passed around a criminal marketplace focused on identity theft. We received the internal alert within two days of the initial exposure.
I hope you have gained something from this series. Breach data is bad in the wrong hands, but an amazing resource for those who will do good things with it. I provide more details tomorrow on episode 269 of the podcast.
