Archive Site Removal Guide
Anything posted to the internet stays online forever. Well, sort of. Services such as Archive.org and Archive.Today aim to preserve all websites, which can be an unwelcome feature for those who wish to erase their past. Fortunately we still have some privacy powers which can be executed to remove undesired content associated with the domains which we own.
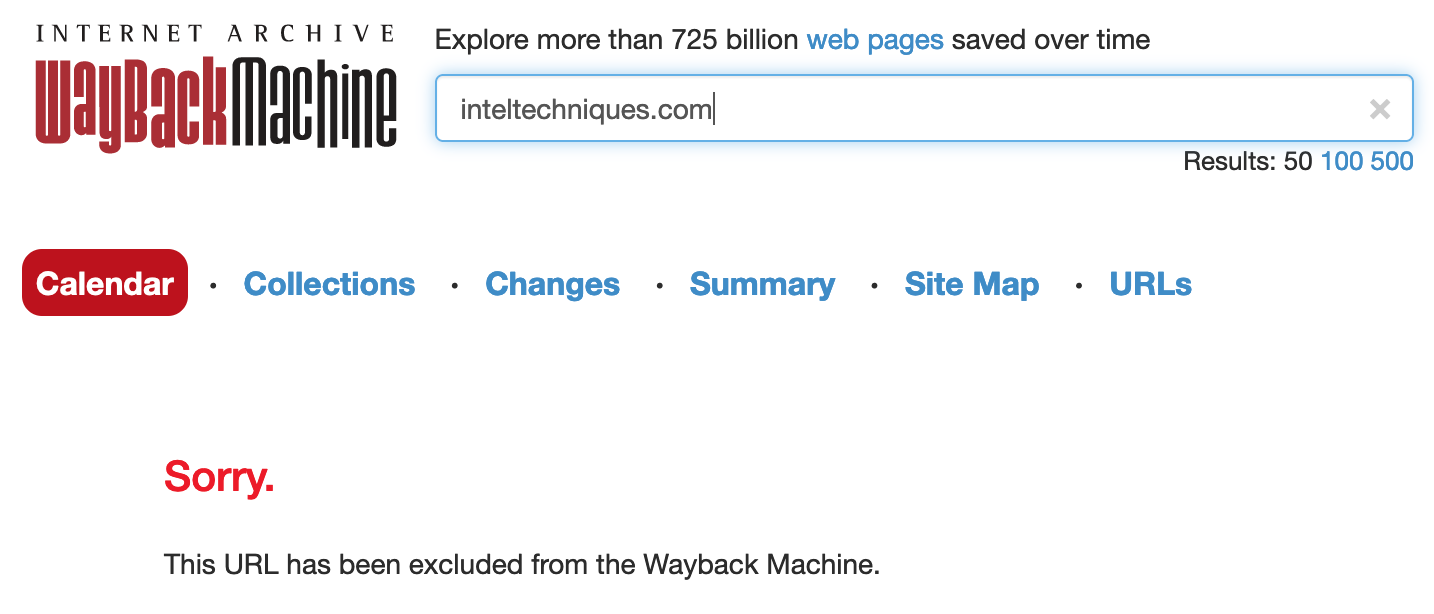
Archive.org Removal
If your website(s) appear on Archive.org, you may want to eliminate any sensitive historical details. This could include an old family photos site or a self-hosted blog which has not aged well. Archive.org now ignores robots.txt and "NOARCHIVE" tags. Conduct ALL of the following for best removal results and consider the option which follows to prevent new exposure.
- Search your domain at https://archive.org/
- Document any domains which display sensitive content.
- Add the following to a robots.txt file on your site.
- (Create a new file if one is not already present.)
- Create a file called verify.txt at the root of your site.
- Add the following text and save.
- Generate an email from an address at the target domain.
- Direct the email to [email protected].
- Create a Subject of "Domain Removal".
- Insert the following text, modifying for your needs.
- Wait 24-48 hours for a response.
- If challenged, provide receipt of domain purchase.
- If required, provide receipt of domain renewal(s).
- Send PDFs, never screen captures.
- After removal confirmation, search to confirm.
- The following is the desired result.
User-agent: archive.org_bot
Disallow: /
please remove from archive.org
I am NAME owner of DOMAIN. I’m officially requesting the immediate removal of my site from all archive.org products. The "User-agent: archive.org_bot Disallow: /" code present in our robots.txt file is not being honored. It can be seen at:
https://DOMAIN/robots.txt
I am requesting removal of DOMAIN from all stored dates, including today, and all days going forward. I have been the sole owner of this domain since inception. I have sent this message from an address hosted at the domain which should be removed. I have also placed a confirmation message at the following link:
https://DOMAIN/verify.txt
Thank you for your prompt attention.
DMCA Notice:
I am the site owner and sole copyright holder for each of the domains cited above. This letter is official notification under Section 512(c) of the Digital Millennium Copyright Act (”DMCA”), and I seek the removal of the aforementioned infringing material from your servers. Archive.org does not have any right or permission to reproduce, sell or display my websites in any way, shape or form. I am providing this notice in good faith and with the reasonable belief that rights I own are being infringed. Under penalty of perjury I certify that the information contained in the notification is both true and accurate, and I am the copyright owner and therefore have the authority to act on behalf of the owner of the copyright(s) involved. Thank you for your prompt assistance with this matter.
NAME
DOMAIN
Archive.org Prevention
- Add a robots.txt file on your site with the following.
- Modify your .htaccess file to include the following.
- If using Cloudflare, add the following to a WAF rule.
User-agent: archive.org_bot
Disallow: /
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (archive.org_bot) [NC]
RewriteRule .* - [R=403,L]
(lower(http.user_agent) contains "archive")
Archive.Today Removal
- Search your domain at https://archive.ph/
- Document any captures which display sensitive content.
- Some URLs may appear as "https://archive.ph/jCqte".
- Click any capture of concern.
- Click "report bug or abuse" in the upper-right.
- Insert your name.
- Insert an email associated with the domain.
- Insert any burner VOIP or generic number.
- Select an "Abuse Type" of "Copyright".
- Send the following message.
- Complete Captchas until "Message Sent" appears.
- After removal confirmation, search to confirm.
- If ignored, submit DMCA to [email protected].
I am the owner of DOMAIN and respectfully request removal of this capture and all other captures from DOMAIN.
DMCA Notice:
I am the site owner and sole copyright holder for each of the domains cited above. This letter is official notification under Section 512(c) of the Digital Millennium Copyright Act (”DMCA”), and I seek the removal of the aforementioned infringing material from your servers. Archive.Today does not have any right or permission to reproduce, sell or display my websites in any way, shape or form. I am providing this notice in good faith and with the reasonable belief that rights I own are being infringed. Under penalty of perjury I certify that the information contained in the notification is both true and accurate, and I am the copyright owner and therefore have the authority to act on behalf of the owner of the copyright(s) involved. Thank you for your prompt assistance with this matter. Thank you.
Archive.Today Prevention
Archive.Today does not honor robots.txt or meta tags within HTML. They also do not specify any unique User Agent when cloning a page. The only way to block them it so block their server IP addresses completely. Add the following to your .htaccess file at the root of your domain.
-
order allow,deny
Deny from 198.245.53.182
Deny from 37.1.213.27
Deny from 5.188.0.77
Deny from 37.1.213.27
allow from all
-
(ip.src eq 198.245.53.182) or (ip.src eq 37.1.213.27) or (ip.src eq 5.188.0.77) or (ip.src eq 37.1.213.27)
Google/Bing Cache Removal & Prevention
If you do not want your site to be historically collected as a "Cache" file and presented within every Google or Bing search, add the following line within the "head" section of every HTML page on your site. If using WordPress, copy it to the header.php file within your theme. Be sure to place this line within "<" and ">" at the beginning and end of it.
-
meta name="robots" content="noarchive"
Archive Content DMCA
You may find content within Archive.org or Archive.Today which violates your copyright. This could be a PDF of your work, a photograph taken and owned by you, or a video which was stolen. If you do not own the domain which hosted this content, then you must rely on a traditional DMCA takedown request. This will be more likely to exist on Archive.org, as Archive.Today does not capture PDFs, videos, and other media. The following email to [email protected] should assist.
-
The following content, to which I hold copyright, has been illegally uploaded to your service, please remove it immediately:
[link to Archive.org page]
The following confirms my claim of copyright:
[link to external proof of ownership page]

